The movement datasets#
In movement, poses or bounding boxes’ tracks are represented
as an xarray.Dataset object.
An xarray.Dataset object is a container for multiple arrays. Each array is an xarray.DataArray object holding different aspects of the collected data (position, time, confidence scores…). You can think of a xarray.DataArray object as a multi-dimensional numpy.ndarray
with pandas-style indexing and labelling.
So a movement dataset is simply an xarray.Dataset with a specific
structure to represent pose tracks or bounding boxes’ tracks. Because pose data and bounding boxes data are somewhat different, movement provides two types of datasets: poses datasets and bboxes datasets.
To discuss the specifics of both types of movement datasets, it is useful to clarify some concepts such as data variables, dimensions,
coordinates and attributes. In the next section, we will describe these concepts and the movement datasets’ structure in some detail.
To learn more about xarray data structures in general, see the relevant
documentation.
Dataset structure#
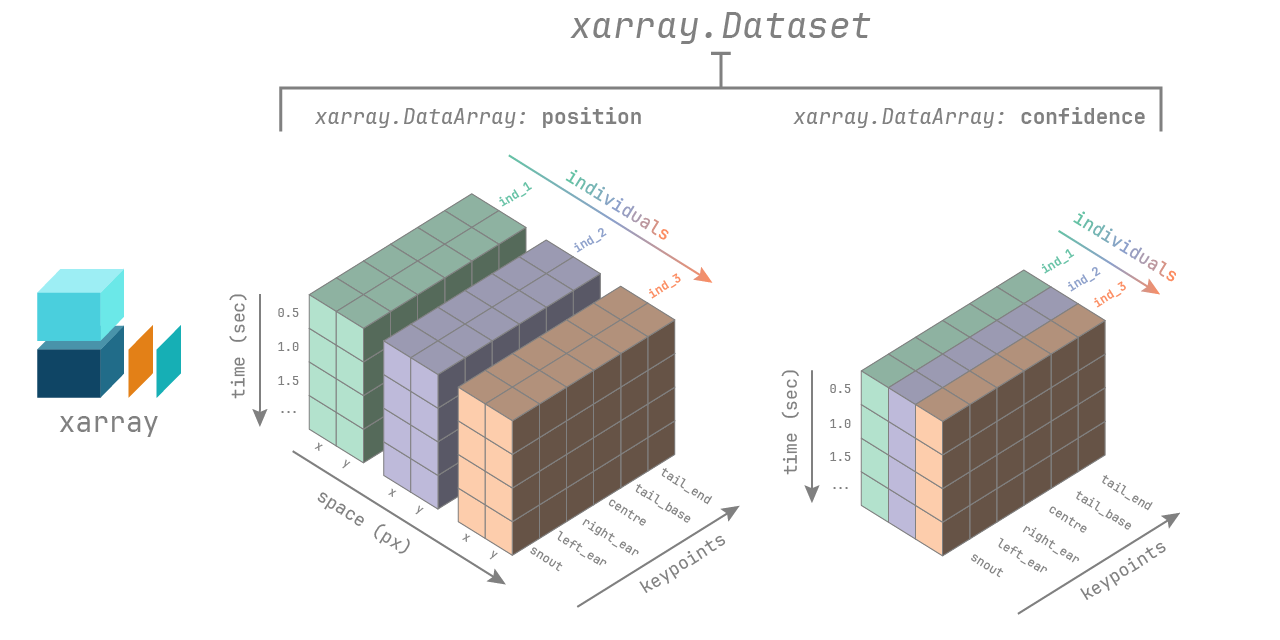
An xarray.Dataset is a collection of several data arrays that share some dimensions. The schematic shows the data arrays that make up the poses and bboxes datasets in movement.#
The structure of a movement dataset ds can be easily inspected by simply
printing it.
To inspect a sample poses dataset, we can run:
from movement import sample_data
ds = sample_data.fetch_dataset(
"SLEAP_three-mice_Aeon_proofread.analysis.h5",
)
print(ds)
and we would obtain an output such as:
<xarray.Dataset> Size: 27kB
Dimensions: (time: 601, individuals: 3, keypoints: 1, space: 2)
Coordinates:
* time (time) float64 5kB 0.0 0.02 0.04 0.06 ... 11.96 11.98 12.0
* individuals (individuals) <U10 120B 'AEON3B_NTP' 'AEON3B_TP1' 'AEON3B_TP2'
* keypoints (keypoints) <U8 32B 'centroid'
* space (space) <U1 8B 'x' 'y'
Data variables:
position (time, individuals, keypoints, space) float32 14kB 770.3 ......
confidence (time, individuals, keypoints) float32 7kB nan nan ... nan nan
Attributes:
fps: 50.0
time_unit: seconds
source_software: SLEAP
source_file: /home/user/.movement/data/poses/SLEAP_three-mice_Aeon...
ds_type: poses
frame_path: /home/user/.movement/data/frames/three-mice_Aeon_fram...
video_path: None
To inspect a sample bounding boxes’ dataset, we can run:
from movement import sample_data
ds = sample_data.fetch_dataset(
"VIA_multiple-crabs_5-frames_labels.csv",
)
print(ds)
and the last command would print out:
<xarray.Dataset> Size: 19kB
Dimensions: (time: 5, individuals: 86, space: 2)
Coordinates:
* time (time) int64 40B 0 1 2 3 4
* individuals (individuals) <U5 2kB 'id_1' 'id_2' 'id_3' ... 'id_89' 'id_90'
* space (space) <U1 8B 'x' 'y'
Data variables:
position (time, individuals, space) float64 7kB 871.8 ... 905.3
shape (time, individuals, space) float64 7kB 60.0 53.0 ... 51.0 36.0
confidence (time, individuals) float64 3kB nan nan nan nan ... nan nan nan
Attributes:
fps: None
time_unit: frames
source_software: VIA-tracks
source_file: /home/user/.movement/data/bboxes/VIA_multiple-crabs_5...
ds_type: bboxes
frame_path: None
video_path: None
In both cases, we can see that the description of the dataset structure refers to dimensions, coordinates, data variables, and attributes.
If you are working in a Jupyter notebook, you can view an interactive
representation of the dataset by typing its variable name - e.g. ds - in a cell.
Dimensions and coordinates#
In xarray terminology,
each axis of the dataset is called a dimension (dim), while
the labelled “ticks” along each axis are called coordinates (coords).
A movement poses dataset has the following dimensions:
time, with size equal to the number of frames in the video.individuals, with size equal to the number of tracked individuals/instances.keypoints, with size equal to the number of tracked keypoints per individual.space, which is the number of spatial dimensions. Currently, we support only 2D poses.
A movement bounding boxes dataset has the following dimensionss:
time, with size equal to the number of frames in the video.individuals, with size equal to the number of tracked individuals/instances.space, which is the number of spatial dimensions. Currently, we support only 2D bounding boxes data. Notice that these are the same dimensions as for a poses dataset, except for thekeypointsdimension.
In both cases, appropriate coordinates are assigned to each dimension.
individualsare labelled with a list of unique names (e.g.mouse1,mouse2, etc. orid_0,id_1, etc.).keypointsare likewise labelled with a list of unique body part names, e.g.snout,right_ear, etc. Note that this dimension only exists in the poses dataset.spaceis labelled with eitherx,y(2D) orx,y,z(3D). Note that bounding boxes datasets are restricted to 2D space.timeis labelled in seconds iffpsis provided, otherwise the coordinates are expressed in frames (ascending 0-indexed integers).
Data variables#
The data variables in a movement dataset are the arrays that hold the actual data, as xarray.DataArray objects.
The specific data variables stored are slightly different between a movement poses dataset and a movement bounding boxes dataset.
A movement poses dataset contains two data variables:
position: the 2D or 3D locations of the keypoints over time, with shape (time,individuals,keypoints,space).confidence: the confidence scores associated with each predicted keypoint (as reported by the pose estimation model), with shape (time,individuals,keypoints).
A movement bounding boxes dataset contains three data variables:
position: the 2D locations of the bounding boxes’ centroids over time, with shape (time,individuals,space).shape: the width and height of the bounding boxes over time, with shape (time,individuals,space).confidence: the confidence scores associated with each predicted bounding box, with shape (time,individuals).
Grouping data variables together in a single dataset makes it easier to keep track of the relationships between them, and makes sense when they share some common dimensions.
Attributes#
Both poses and bounding boxes datasets in movement have associated metadata. These can be stored as dataset attributes (i.e. inside the specially designated attrs dictionary) in the form of key-value pairs.
Right after loading a movement dataset, the following attributes are created:
fps: the number of frames per second in the video. If not provided, it is set toNone.time_unit: the unit of thetimecoordinates (eitherframesorseconds).source_software: the software that produced the pose or bounding boxes tracks.source_file: the path to the file from which the data were loaded.ds_type: the type of dataset loaded (eitherposesorbboxes).
Some of the sample datasets provided with
the movement package have additional attributes, such as:
video_path: the path to the video file corresponding to the pose tracks.frame_path: the path to a single still frame from the video.
You can also add your own custom attributes to the dataset. For example, if you would like to record the frame of the full video at which the loaded tracking data starts, you could add a frame_offset variable to the attributes of the dataset:
ds.attrs["frame_offset"] = 142
Working with movement datasets#
Using xarray’s built-in functionality#
Since a movement dataset is an xarray.Dataset, you can use all of xarray’s intuitive interface
and rich built-in functionalities for data manipulation and analysis.
For example, you can:
access the data variables and attributes of a dataset
dsusing dot notation (e.g.ds.position,ds.fps),index and select data by coordinate label (e.g.
ds.sel(individuals=["individual1", "individual2"])) or by integer index (e.g.ds.isel(time=slice(0,50))),use dimension names for data aggregation and broadcasting, and
use
xarray’s built-in plotting methods.
As an example, here’s how you can use the sel method to select subsets of
data:
# select the first 100 seconds of data
ds_sel = ds.sel(time=slice(0, 100))
# select specific individuals or keypoints
ds_sel = ds.sel(individuals=["individual1", "individual2"])
ds_sel = ds.sel(keypoints="snout")
# combine selections
ds_sel = ds.sel(
time=slice(0, 100),
individuals=["individual1", "individual2"],
keypoints="snout"
)
The same selections can be applied to the data variables inside a dataset. In that case the selection operations will
return an xarray.DataArray rather than an xarray.Dataset:
position = ds.position.sel(
individuals="individual1",
keypoints="snout"
) # the output is a data array
Accessing movement-specific functionality#
movement extends xarray’s functionality with a number of convenience
methods that are specific to movement datasets. These movement-specific methods are accessed using the
move keyword.
For example, to compute the velocity and acceleration vectors for all individuals and keypoints across time, we provide the move.compute_velocity and move.compute_acceleration methods:
velocity = ds.move.compute_velocity()
acceleration = ds.move.compute_acceleration()
The movement-specific functionalities are implemented in the
movement.move_accessor.MovementDataset class, which is an accessor to the
underlying xarray.Dataset object. Defining a custom accessor is convenient
to avoid conflicts with xarray’s built-in methods.
Modifying movement datasets#
The velocity and acceleration produced in the above example are xarray.DataArray objects, with the same dimensions as the
original position data variable.
In some cases, you may wish to
add these or other new data variables to the movement dataset for
convenience. This can be done by simply assigning them to the dataset
with an appropriate name:
ds["velocity"] = velocity
ds["acceleration"] = acceleration
# we can now access these using dot notation on the dataset
ds.velocity
ds.acceleration
Custom attributes can also be added to the dataset:
ds.attrs["my_custom_attribute"] = "my_custom_value"
# we can now access this value using dot notation on the dataset
ds.my_custom_attribute
We can also update existing data variables in-place, using the update() method. For example, if we wanted to update the position
and velocity arrays in our dataset, we could do:
ds.update({"position": position_filtered, "velocity": velocity_filtered})